
Obsługa braków danych w zużyciu energii elektrycznej
Podczas analizy danych dotyczących rzeczywistego zużycia energii elektrycznej często musimy mierzyć się z problemem występujących w nich braków. Zjawisko to może mieć różnorodne przyczyny. Wśród nich można wymienić następujące: techniczne błędy pomiarowe, brak udostępnionych danych przez OSD lub błędy przetwarzania.
Jednym z podstawowych kroków na etapie przygotowania danych powinna być imputacja braków danych, co umożliwi poprawne działanie wielu metod machine learning na kolejnych etapach. Kluczowym momentem było wyznaczenie wartości granicznej – jaka maksymalna liczba oraz długość przerwy w odczytach rzeczywistych może zostać poddana imputacji, aby nie zaburzyć faktycznego przebiegu zużycia.
Dla wszystkich punktów poboru zbadano rozkład braków i wyznaczono statystyki. Poniżej przedstawiono roczne przebiegi zużycia rzeczywistego dla dwóch przykładowych punktów posiadających braki (te zostały oznaczone na czerwono).
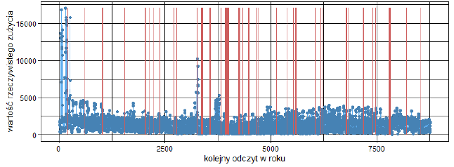
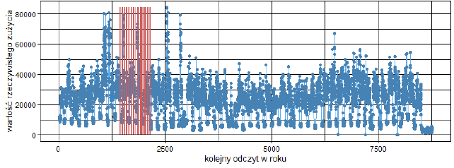
Obraz 1 Przebiegi zużycia rzeczywistego dla dwóch przykładowych punktów z brakami danych
Już na przykładzie tych dwóch punktów można zauważyć, że rozkład zarówno zużycia jak i występujących w nim braków jest zróżnicowany. W związku z tym ważny jest wybór takiej metody, która na tak zróżnicowanych danych pozwoli uzyskać satysfakcjonujące wyniki.
Wybór najlepszej metody imputacji był zadaniem wieloetapowym. Ocena skuteczności metod imputacji wymagała z jednej strony znajomości wartości rzeczywistych, a z drugiej sztucznie wytworzonych braków danych. W pierwszym kroku symulowano losowy proces powstawania braków danych na punktach poboru z kompletnym przebiegiem zużycia. W przypadku dostarczonych danych przyjęto generalne założenie, że proces mechanizmu powstawania braków nie jest w pełni losowy, ale nie można zidentyfikować reguły generującej występowanie braków. Z tego względu zdecydowano się na przeprowadzenie trzech eksperymentów, z których każdy oparto na innej metodzie generowania braków.
W przeprowadzonych pracach analitycznych rozważano trzy główne metody imputacji braków danych, które zostały wyodrębnione na skutek wcześniejszych analiz opartych o charakterystykę badanych szeregów czasowych. Każdą z metod stosowano w trzech wariantach związanych z uwzględnieniem sezonowości szeregu czasowego oraz sposobu uwzględnienia informacji wykorzystanej do imputacji. Warianty każdej metody opierały się na wykorzystaniu średniej ruchomej z różnymi sposobami uwzględnienia informacji „najbliższej” czasowo brakowi.
Wybrane metody i warianty imputacji porównano na podstawie błędów 𝑀𝐴𝑃𝐸 (mean absolute percentage error) oraz 𝑀𝐴𝐸 (mean absolute error) wyliczonych dla poszczególnych punktów poboru na podstawie wartości rzeczywistych oraz wartości imputowanych.
Na poniższych wykresach przedstawiono wartości kwartyli dla poszczególnych metod i ich wariantów w podziale na 3 metody wstawiania braków.
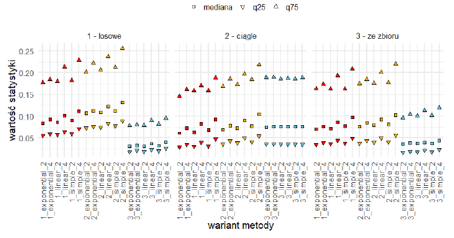
Obraz 2 Kwartyle wartości MAPE dla poszczególnych metod imputacji dla trzech metod wstawiania braków
W oparciu o wykresy oraz szczegółowe statystyki błędów MAPE i MAE widać wyraźną przewagę trzeciej metody imputacji w wariancie 3_exponential_2. W związku z tym metoda ta została wybrana do imputacji rzeczywistych braków danych.
Na poniższym wykresie zaprezentowano działanie metod dla fragmentu szeregu, w którym utworzono sztuczne braki w dniach od 9 do 12 maja.
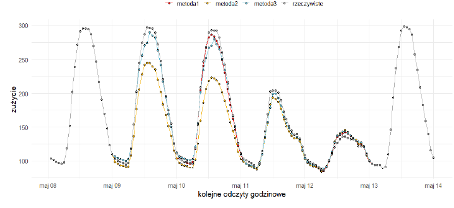
Obraz 3 Zużycie rzeczywiste dla wybranego punktu poboru oraz wartości imputacji
Po przeprowadzonej imputacji stwierdzono, że uzyskany rozkład błędów MAE jest bardzo zbliżony do rozkładu wartości MAE sprzed imputacji. Można więc stwierdzić, że imputacja brakujących wartości nie zaburzy rzeczywistego przebiegu zużycia, a jednocześnie pozwoli w kolejnych etapach projektu na zastosowanie zaawansowanych metod analizy danych, których działanie na danych z brakami byłoby utrudnione lub wręcz niemożliwe.